FlashMHF: Turning the FFN into “Multi-Head + Flash” — Notes on Flash Multi-Head FFNFlashMHF:把 FFN 做成“多头 + Flash” —— Flash Multi-Head FFN 笔记
FFN + SRAM fused kernel: improves perplexity/downstream accuracy while cutting peak memory by 3–5x and reaching up to 1.08x inference speedup.FFN + SRAM 在线融合 kernel,在提升困惑度/下游指标的同时把峰值显存降 3–5x,并带来最高 1.08x 推理加速。
TL;DR (4 things to remember)
- Motivation: An FFN (especially SwiGLU) is structurally very close to “single-head attention”, except
softmaxis replaced by element-wise nonlinearity/gating — so FFNs should also benefit from the multi-head principle. - Why naïve MH-FFN breaks: (1) activation memory scales linearly with head count (H copies of large intermediates); (2) as models scale, the ratio
d_ff / d_hexplodes, causing a scaling imbalance and degraded performance. - What FlashMHF changes: use parallel FFN sub-networks + gating to keep a balanced effective expansion ratio per head; and use an I/O-aware fused kernel (SRAMFFN) to compute
SwiGLUonline without materializing huge intermediates in HBM. - Result: for 128M–1.3B pretraining, compared to SwiGLU FFN: better perplexity/downstream accuracy, 3–5x lower peak memory, and up to 1.08x faster inference (avg ~1.05x).

1) Background: why touch the FFN?
Inside a Transformer block, attention gets most of the spotlight — but the FFN/MLP is a large chunk of parameters and compute. FlashMHF targets a pragmatic goal: improve FFN expressivity like multi-head attention does, without blowing up memory.
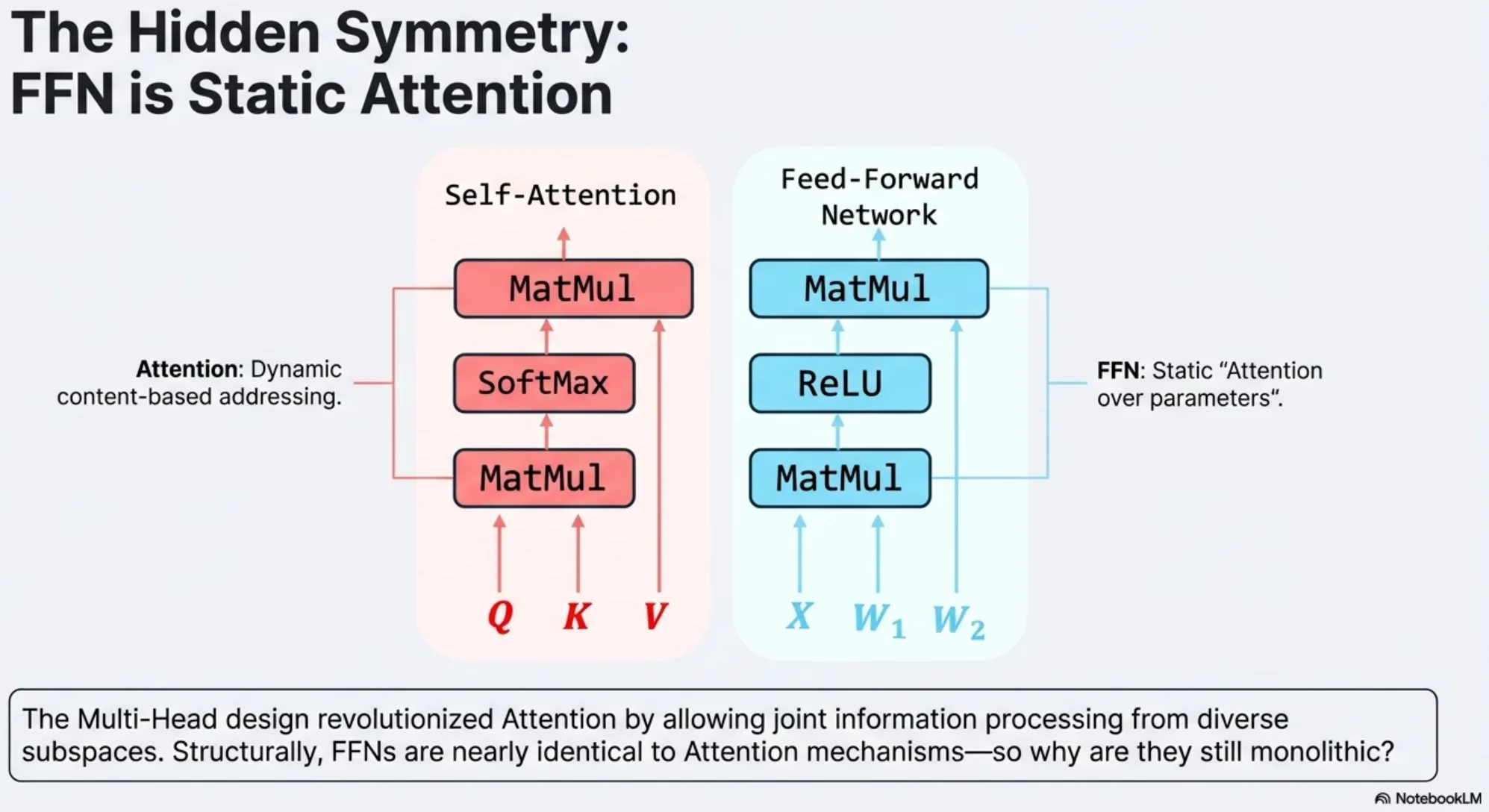
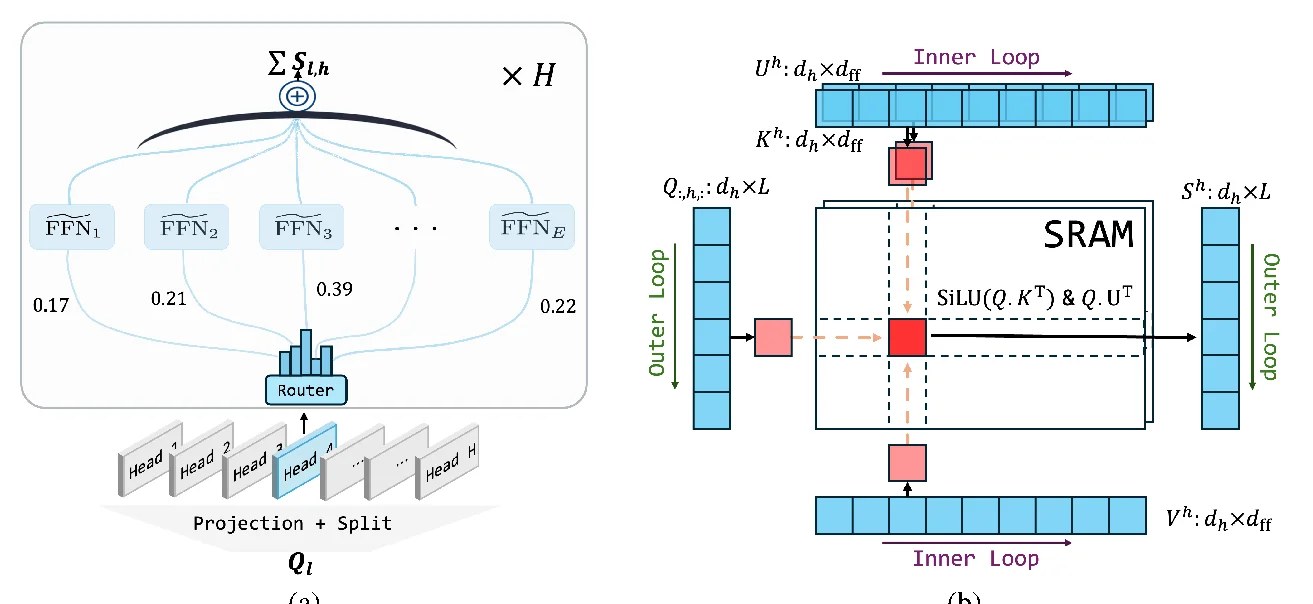
2) “FFN ≈ Attention” structural symmetry (the key viewpoint)
The paper rewrites SwiGLU as a kind of “generalized attention”: replace softmax(QK^T) with an element-wise nonlinearity ϕ, then multiply by V.
In a more direct form (ignoring batch/head dims):
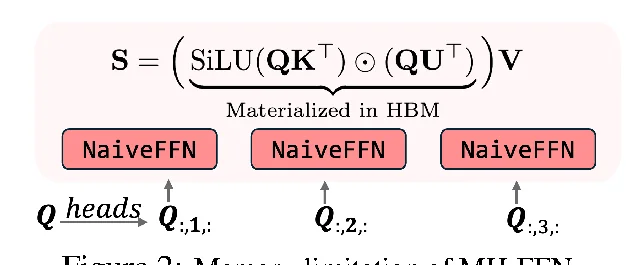
A = SiLU(Q K_g^T) ⊙ (Q K_u^T)
O = A VThis explains the direction: if multi-head is a strong inductive bias for attention, maybe FFN can also be decomposed into heads to gain expressivity.
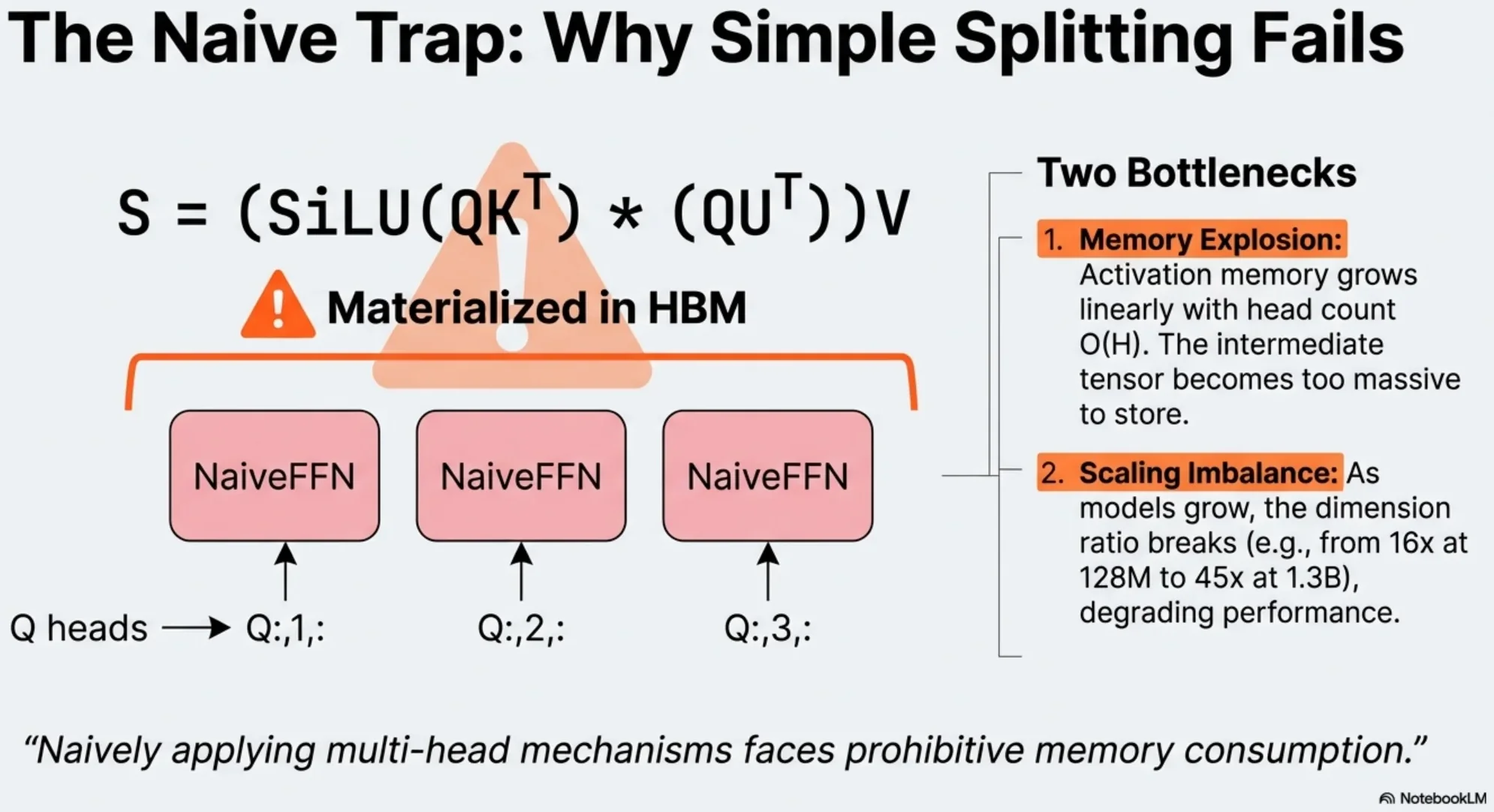
3) Two fatal issues of naïve MH-FFN
3.1 Memory pressure: intermediate activations × H
A naïve multi-head FFN produces one large intermediate activation per head (roughly L × d_ff). More heads → closer to “multiply peak activation memory by H”.
3.2 Scaling imbalance: d_ff / d_h blows up with model size
MH-FFN often inherits the MHA habit of keeping d_h fixed (e.g. 128). As the model scales, d_ff grows, so d_ff / d_h becomes too large and drifts away from the empirically good range.
The paper gives a simple sanity check (naïve MH-FFN with d_h = 128):
- 128M:
d_ff / d_h = 2048 / 128 = 16 - 370M:
d_ff / d_h = 2688 / 128 = 21 - 1.3B:
d_ff / d_h = 5760 / 128 = 45
4) FlashMHF: fix scaling + fix memory
4.1 Parallel FFN sub-networks (dense-MoE-like, but every token aggregates)
High-level idea:
- Each head no longer has a single monolithic FFN path; instead it has E parallel sub-networks.
- For each token, compute gating weights within the head and aggregate the E sub-network outputs.
This keeps each sub-network at a reasonable internal width/expansion ratio, which directly combats the d_ff / d_h imbalance. Since aggregation is dense, there is no routing / all-to-all overhead.
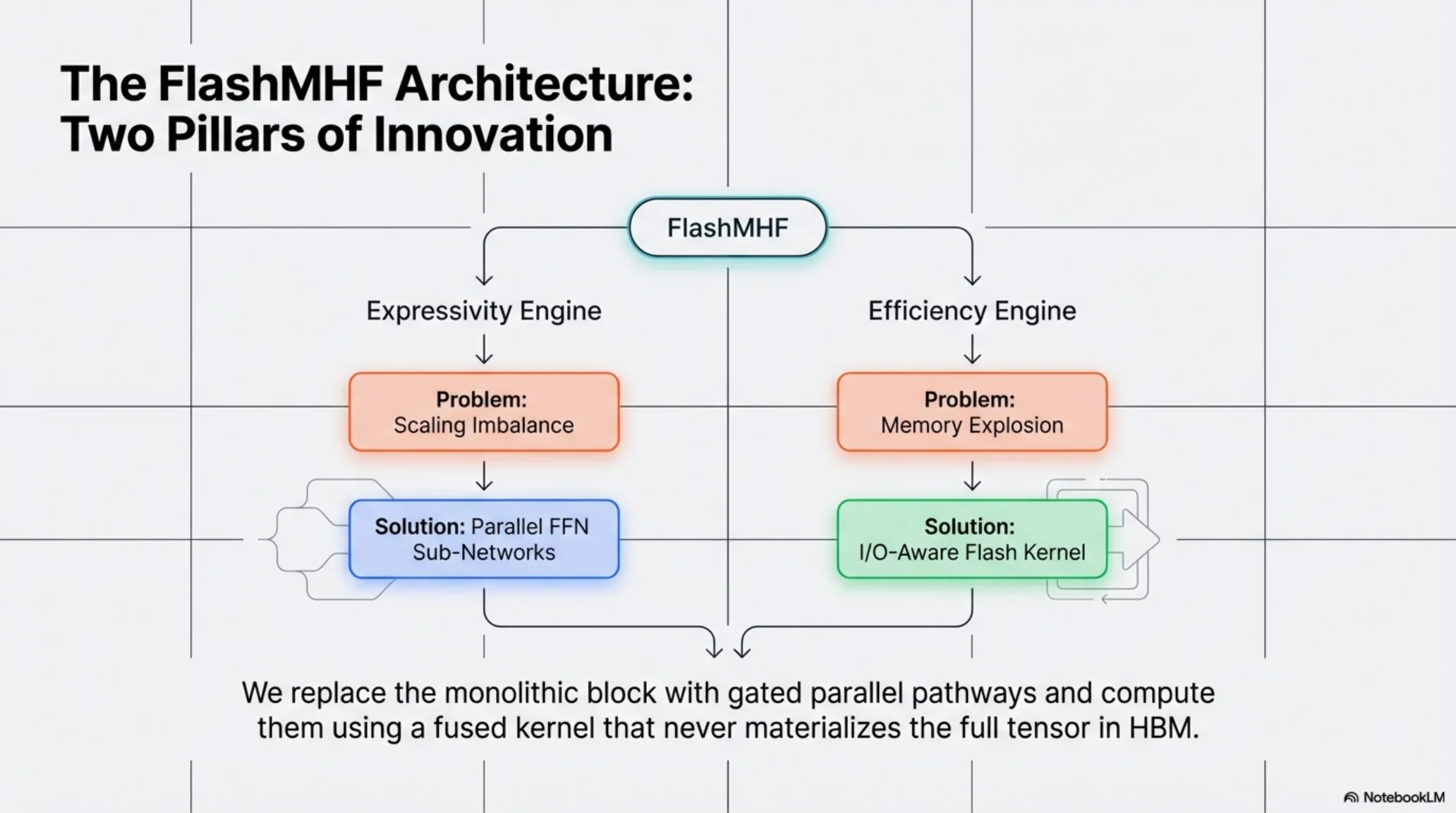
4.2 I/O-aware flash algorithm (SRAMFFN: blockwise online compute)
The goal is simple: avoid writing
A = SiLU(QK^T) ⊙ (QU^T) # hugeto HBM and reading it back.
FlashMHF’s fused kernel blocks K/U/V along d_ff, performs blockwise compute on SRAM, and accumulates directly into O (“finish a block → add to O → discard the block activation”). Peak memory drops from “store giant intermediates” to “store an output accumulator”.
5) Results (only the key numbers)
5.1 Language modeling validation loss (PG19 val, lower is better)
From Table 1 (370M / 1.3B):
- 370M Baseline (SwiGLU): 3.030
- 370M FlashMHF:
d_h=643.046,d_h=1283.014,d_h=2563.029 - 1.3B Baseline (SwiGLU): 2.843
- 1.3B FlashMHF:
d_h=642.849,d_h=1282.793,d_h=2562.799
Empirically, d_h=128 tends to be a sweet spot: too small bottlenecks each head; too large reduces the number of heads and loses subspace diversity.
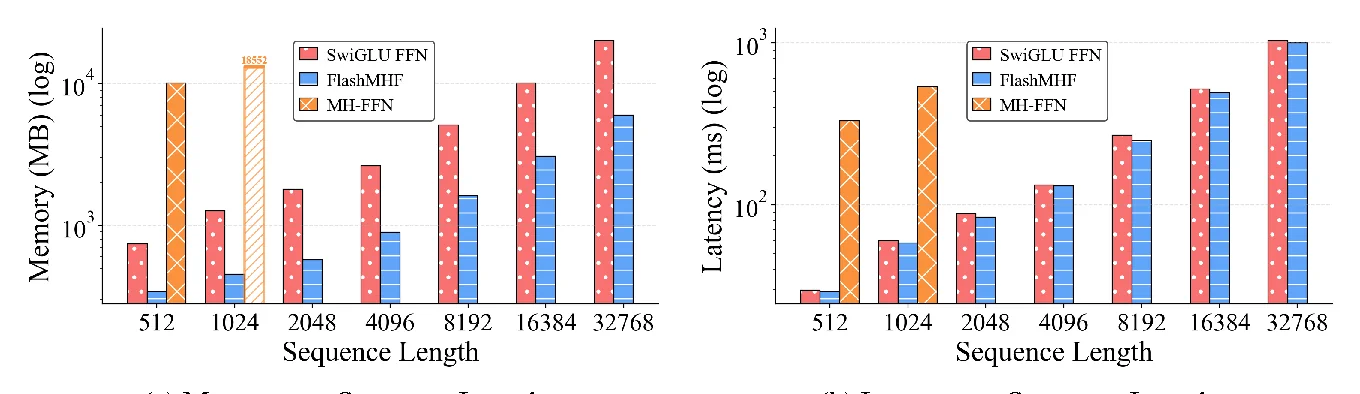
5.2 Efficiency: 3–5x memory, up to 1.08x speed
On Hopper benchmarks (Section 4.3):
- Peak memory: 3–5x lower than a standard SwiGLU FFN
- Inference latency: up to 1.08x speedup (avg ~1.05x)
TL;DR(我想记住的 4 件事)
- 动机:FFN(特别是 SwiGLU)在形式上和“单头 attention”非常像,只是把
softmax换成了逐元素的非线性/门控,因此也值得做成 multi-head。 - naïve MH-FFN 为什么不行:一是显存压力随 head 数线性增长(中间激活要存 H 份);二是随模型变大出现缩放失衡(
d_ff / d_h变得过大),导致效果不再提升甚至变差。 - FlashMHF 怎么做:用 parallel FFN sub-networks + gating 把每个 head 的有效扩展比拉回合理区间;再用 I/O-aware fused kernel(SRAMFFN)在线算
SwiGLU,不把巨大的中间激活落到 HBM。 - 结果:在 128M–1.3B 预训练规模上,相比 SwiGLU FFN:困惑度/下游任务更好;峰值显存节省 3–5x;推理速度最高 1.08x(平均约 1.05x)。
1) 背景:为什么要动 FFN?
Transformer block 里,Attention 经常被讨论,但 FFN(MLP)其实是参数量与算力的大头之一。FlashMHF 关注的是:能不能把 FFN 的表达力做得像 multi-head attention 一样更强,同时别让显存炸掉。
2) “FFN ≈ Attention”的结构对称性(论文核心视角)
论文把 SwiGLU 写成一种“广义 attention”的形式:把 softmax(QK^T) 换成一个逐元素非线性 ϕ,然后再乘 V。
用更直观的写法(忽略 batch/head 维):
A = SiLU(Q K_g^T) ⊙ (Q K_u^T)
O = A V这解释了为什么作者会尝试把 FFN 做成 multi-head:既然 attention 的 multi-head 是强 inductive bias,那么 FFN 也可能受益。
3) Naïve MH-FFN 的两个致命问题
3.1 显存压力:中间激活 × H
naïve 的多头 FFN 会在每个 head 里各自算一份中间激活(形状大致是 L × d_ff),head 数越多,就越接近“把显存按 head 数翻倍”。
3.2 缩放失衡:d_ff / d_h 随规模爆炸
作者指出,MH-FFN 常沿用 MHA 的习惯把 d_h 固定(例如 128),但随着模型变大,FFN 的 d_ff 会增长,于是 d_ff / d_h 变得越来越大,偏离经验上的合理区间,导致可扩展性差。
论文里给了一个直观的量级对比(naïve MH-FFN,d_h = 128):
- 128M:
d_ff / d_h = 2048 / 128 = 16 - 370M:
d_ff / d_h = 2688 / 128 = 21 - 1.3B:
d_ff / d_h = 5760 / 128 = 45
4) FlashMHF:两条线同时解决“缩放失衡 + 显存压力”
4.1 Parallel FFN Sub-networks(像 dense MoE,但每个 token 都聚合)
做法(直觉版):
- 每个 head 不再只走一条大的 FFN 路径,而是拆成 E 条并行的子网络(sub-networks)。
- 对每个 token,在该 head 内算一组 gating 权重,对 E 条子网络输出做加权求和。
这样做的好处是:每条子网络可以保持更合理的内部宽度/扩展比,从结构上缓解 d_ff / d_h 失衡的问题;而且因为是 dense 聚合,不需要路由/通信开销。
4.2 I/O-aware Flash Algorithm(SRAMFFN:在线分块,避免落大激活)
核心目标:别把
A = SiLU(QK^T) ⊙ (QU^T) # 体积很大这个 A 完整写到 HBM 再读回来。
FlashMHF 的 fused kernel 把 K/U/V 沿 d_ff 分块,在 SRAM 里做块内计算并把贡献累加到输出 O 上(“算完一块就加到 O,然后丢掉这块的 A”)。因此峰值显存从“存大中间激活”变成“只存输出累加器”,显著下降。
5) 实验结果(摘最关键的数字)
5.1 语言建模验证损失(PG19 val,越低越好)
论文 Table 1(370M / 1.3B):
- 370M Baseline(SwiGLU):3.030
- 370M FlashMHF:
d_h=643.046,d_h=1283.014,d_h=2563.029 - 1.3B Baseline(SwiGLU):2.843
- 1.3B FlashMHF:
d_h=642.849,d_h=1282.793,d_h=2562.799
经验上作者也观察到:d_h=128 往往是一个 sweet spot(太小瓶颈、太大 head 数变少导致多样性下降)。
5.2 效率:显存 3–5x,速度最高 1.08x
在 Hopper 架构的 benchmark 里(论文 4.3):
- 峰值显存:相对 SwiGLU FFN 降低 3–5 倍
- 推理延迟:最高 1.08x 加速(平均约 1.05x)