About Me
I am an M.S. student in Computer Science at UC San Diego, advised by Prof. Hao Zhang in the Hao AI Lab, and I hold a B.S. from ShanghaiTech University advised by Prof. Kewei Tu. My research lies at the intersection of Machine Learning Systems and generative models, with a focus on efficient, scalable video generation and world models.
At the Hao AI Lab, I am a core contributor to FastVideo, an open-source framework for fast and scalable video generation. I helped build and ship DreamVerse, a real-time video generation workspace that streams 1080p clips on a single GPU — contributing audio–visual continuity to the generation pipeline and accelerating backend inference through kernel benchmarking and fusion. I also train action-conditioned world models on distributed multi-node H200 clusters and contribute training infrastructure, custom GPU kernels, and code reviews across the project.
Before UC San Diego, I was the lead author of FlashMHF, a Multi-Head FFN architecture backed by IO-aware Triton/CUDA kernels that cuts peak memory by 3–5x. At Alibaba Ant Group, I integrated Hierarchical Sparse Attention into the SGLang inference framework and built custom Flash GPU kernels in ThunderKittens/CUDA/Triton.
Publications
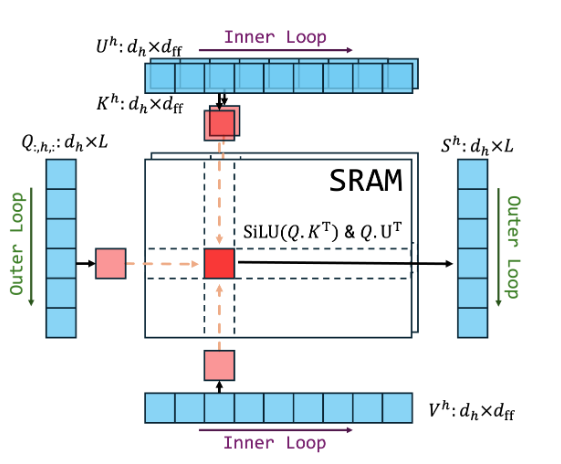
Flash Multi-Head Feed-Forward Network
arXiv Preprint, 2025
We propose Flash Multi-Head FFN (FlashMHF), a novel architecture replacing standard FFNs in Transformers. Backed by IO-aware Triton/CUDA kernels and dynamic sub-networks, FlashMHF reduces peak memory by 3-5x and accelerates inference while improving performance over SwiGLU.
Projects

DreamVerse: Real-Time Video Generation
Open-Source Release, May 2026
A real-time video generation workspace for "vibe directing" — steering generation through natural-language iteration instead of one-shot prompting. Built on the open-weights LTX-2 model with a FastVideo backend runtime and a Blackwell-optimized pipeline (NVFP4 inference, FA4, torch.compile), streaming 30s 1080p clips with under 5s wait on a single NVIDIA B200. As a core contributor, I built session-based audio–visual continuity for seamless multi-segment generation and accelerated backend inference through kernel benchmarking and fusion.

FastVideo
Open-Source Project, Oct 2025 - Present
Building scalable and efficient training infrastructure for video generation. Training action-conditioned world models and accelerating inference by SOTA distillation methods. Proposed a novel data curation pipeline for high-quality action-labeled video datasets.
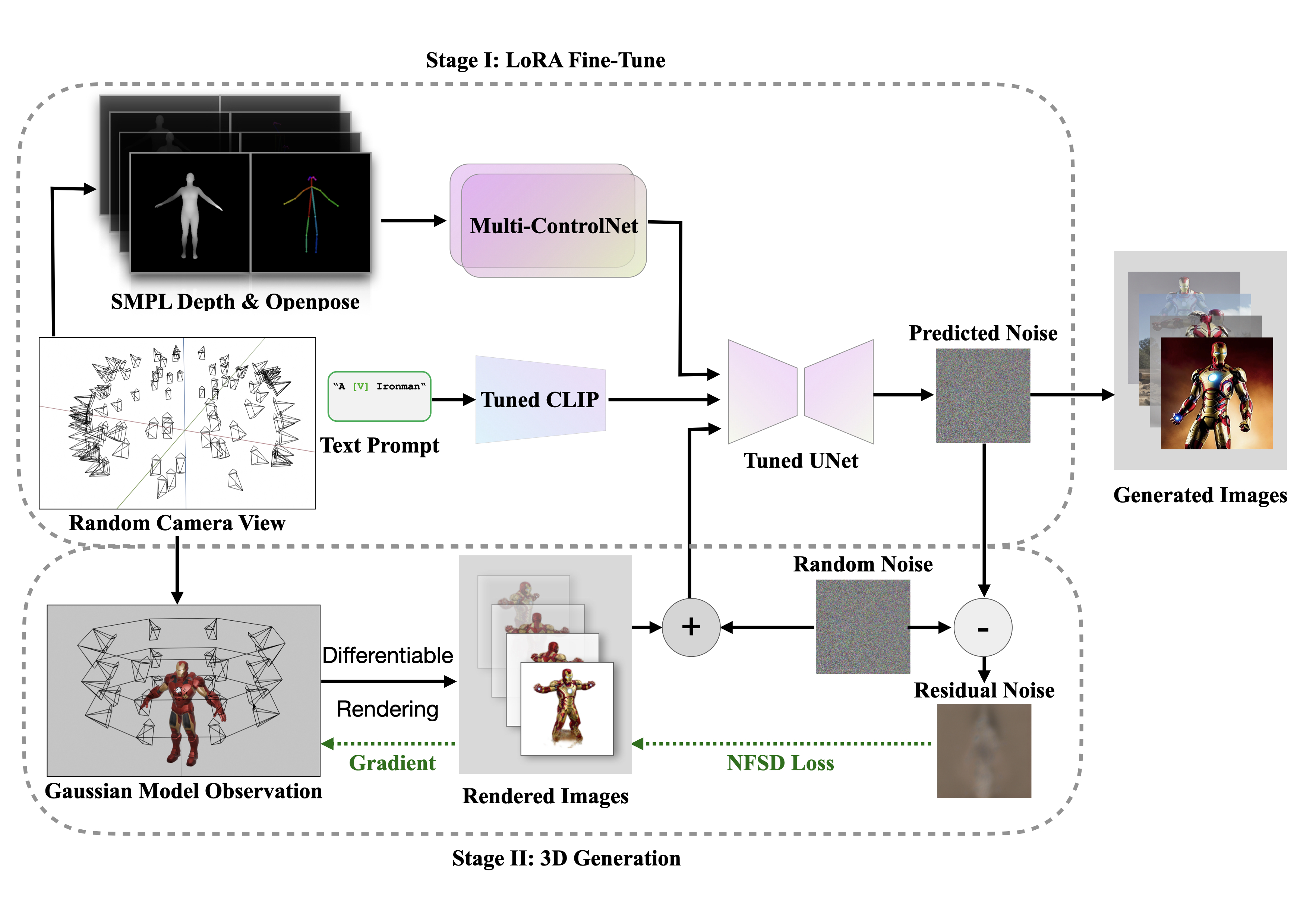
Enhancing 3D Character Generation with ControlNet and LoRA
EECS 182/282A | Deep Neural Networks, UC Berkeley, 2023
A project exploring enhanced 3D character generation techniques using ControlNet and LoRA for improved control and quality in generative models.

CUDA/C++ Parallel Image Rendering
Personal Project, 2023
Built a C++ path tracer supporting Lambertian, metal, dielectric, and emissive materials. Implemented motion blur, depth of field, and volumetric effects. Accelerated rendering via CUDA parallelization and importance sampling, achieving ~200× speedup vs. single-threaded CPU baseline.
Education

University of California, San Diego
Sep 2025 - Dec 2026 (Expected)Master of Science in Computer Science and Engineering
La Jolla, CA

University of California, Berkeley
Aug 2023 - Jan 2024Exchange Student, EECS Department
Berkeley, CA

ShanghaiTech University
Sep 2021 - Jun 2025Bachelor of Engineering in Computer Science and Technology
Shanghai, China